
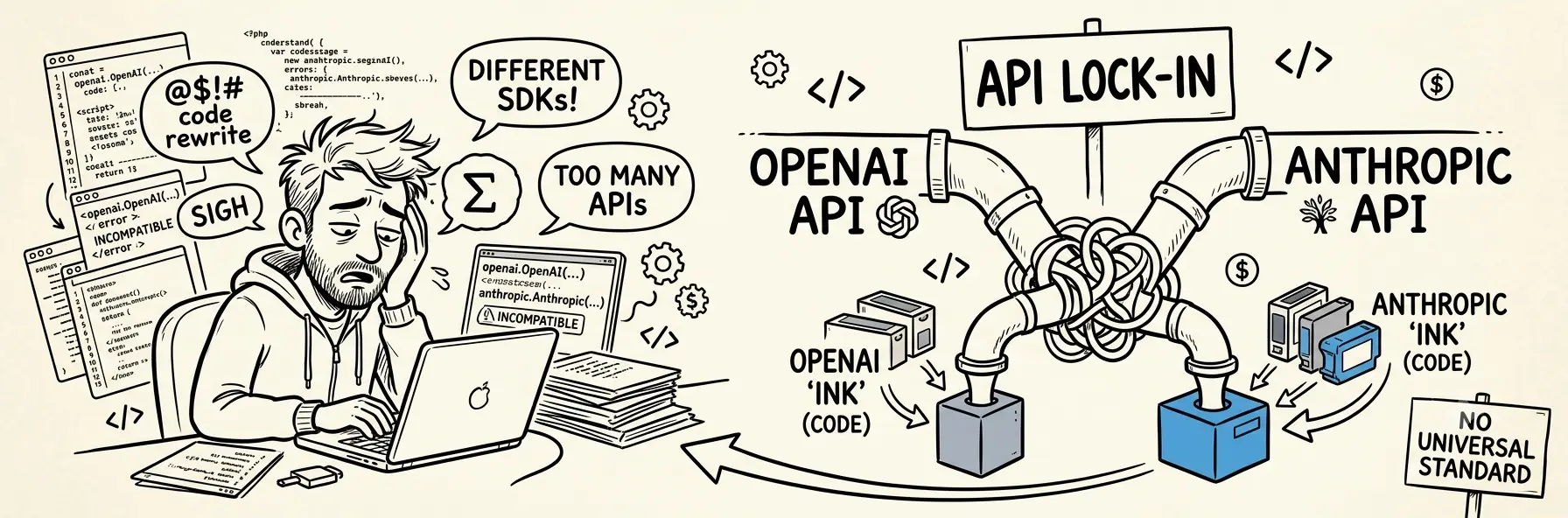
最近在做一些 AI 应用集成的工作,需要在不同模型之间切换。然后我就发现了一个问题——OpenAI 和 Anthropic 的 API 原来是不兼容的。
从一次简单的换模型说起
如果我已经在用 OpenAI 的 GPT-4o,现在想同个工具试试 Claude 3.5 Sonnet。一般来说,换个 endpoint、改个 model 名字就行了吧?然而并不是… 下面是 OpenAI 的官方SDK调用方式:
1 | # OpenAI 的调用方式 |
这是ChatGPT火爆以来,大家都基本遵守的协议或调用方式。但是随着技术的高速发展,Anthropic 提出了他们自己的方式:
1 | # Anthropic 的调用方式 |
虽然看上去差别不大,但实际处理起来还是有点费事的:
- 客户端 SDK 不同:一个是
openai包,一个是anthropic包,没法混用 - 参数命名不同:
max_tokens的位置和写法不一样 - 返回格式不同:OpenAI 返回流式用
for chunk in response,Anthropic 用for event in response还得判断 event type - stream 实现细节不同:连处理流式响应都得重写
- Tool/function calling 协议不同:这是最要命的——如果你的应用用了 function calling,切换模型基本等于重写整个调用层
- 系统提示词格式不同:OpenAI 是
systemrole,Anthropic 有自己的 system prompt 参数 - 图像输入格式不同:连传张图都得用不同格式
我想这也是为什么,DeepSeek会专门弄个Anthropic兼容的端点了…
这让我想起了打印机
这场景太熟悉了。当年买打印机,机器本身可以卖得很便宜,但墨盒/硒鼓一定是专用的。A牌子的打印机只能用 A 的墨盒,B 牌子则只能用 B 的。第三方兼容墨盒要么被固件封锁,要么被”官方认证芯片”挡住。
我想 OpenAI 和 Anthropic 的 API 不兼容除了”技术债”或”设计理念不同”,背后也有很清晰的商业逻辑:
- 切换成本:你在一家 API 上写了大量代码、做了深度集成,就很难说换就换。即使另一家模型更好、更便宜,心理和工程上的迁移成本都在那里。
- 数据壁垒:虽然 API 不直接锁数据,但当你深度依赖某个平台的特性(比如 OpenAI 的 structured output、Anthropic 的 extended thinking),就被绑得更死了。
这不就是数字时代的打印机耗材吗?机器(API 标准)本身可以开放,但耗材(实现细节、生态工具、专属特性)是专用的。
太阳底下无新事
从打印机到智能手机充电口,从游戏主机独占到云服务厂商的锁定策略,商业公司通过制造不兼容来绑架用户,这招确实也不新鲜了。
我作为一个开发者兼使用者,除了抱怨… 也只能该用还是用了… 哎。