
之前曾经尝试过Scrapy爬用药网站的信息, 但是没有做记录, 这次又帮同学爬了点东西所以趁机记录一下.
简介
Scrapy是Python下的一个专门用来爬网站的爬虫框架. 相比自己使用request的等比较基础的报来发送请求与解析信息, Scrapy自带了请求处理, 返回解析, 异常处理, 任务队列管理等等一系列功能, 使我们能更好更专业的进行数据爬取工作.
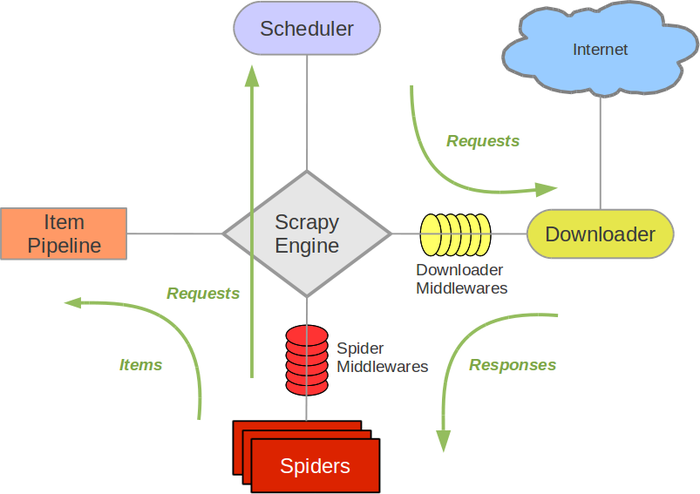
当然代价就是… 上手门槛变高了一丢丢, 因为得先理解这个框架里的一些基本概念和工作原理. 我当初直接看菜鸟教程给的图… 反正是一脸蒙逼的:
案例操作
本着简化的原则… 我只记录实际操作中需要了解的部分.
1. 新建项目
首先, Scrapy作为框架, 不需要使用者从头开始一行一行写代码, 而是在既有模板下编写操作相关的方法就行. 开启一个新项目时, 使用scrapy startproject demo创建新的项目.

创建完成后, 项目目录下有一堆东西, 不用所有文件都了解, 知道下面几个就行了:
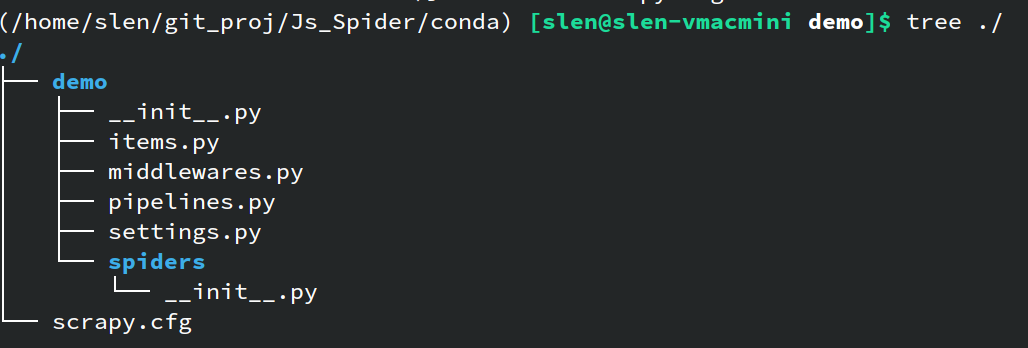
demo/spiders: 存放爬虫文件的目录, 刚刚建立项目而没有创建爬虫的话, 这个目录下除了__init__.py是没有东西的, 爬虫的具体内容后面介绍demo/settings.py: 爬虫的配置文件, 请求头, 反爬协议, 任务间隔, COOKIE设置等等等的设置全在里头, 大部分设置看文件内的注释条目就能看懂, 对应设置就行demo/pipelines.py: 对应上面示例图里的Item Pipeline, 这里是定义对Item处理方案的地方, 当需要使用item这一内置的对象来收集目标信息时需要设置demo/items.py: 定义Item的文件, 同上, 需要使用item的时候需要在文件内定义item(主要是定义一个item里头要存啥)
2. 新建爬虫
爬虫文件需要进一步运行scrapy genspider来生成, 比如项目下scrapy genspider dSpider www.sample.com就会在demo/spiders/文件夹下生成一个名字为dSpider.py的爬虫文件, 里面的内容大概是这样:
1 | import scrapy |
使用改爬虫本质上就是对生成的这个爬虫内的方法进行改写, 比如我这次写的:
1 | import scrapy |
方法parse的写的是爬虫在访问url获取页面信息后如何进行处理. 这里就有多种处理方式了. 如果想按照Scrapy推荐的方式来, 可以像上面一样, 将需要的信息从响应内容中提取出来, 然后存到item中并返回, 这样获取到的信息就会以打包好的item的方式进入千米您提到的Item Pipeline中, 在那里就可以编写获取到Item后最终如何处理和保存数据.
如果嫌麻烦, 想自己处理, 也可以在parse方法内就直接处理掉, 比如直接建立数据框, 然后直接将这些内容写到文件. 这样就不用走后面的东西了.
具体采取哪种方式视任务需要而定就好.
3. 处理Item
如果采取使用item的方式, 那就还要去demo/pipelines.py中编写处理数据的部分:
1 | # Define your item pipelines here |
open_spider方法是爬虫启动时会执行的代码, 一般是打开需要写的文件或者与需要写入的数据库进行连接和初始化process_item部分则是爬虫每返回一个item时, 对这个item进行何种处理, 我这里做的是把原始得到的json字串存到文件中, 另外是把key做替换后, 存到一个字典中close_spider方法是当爬虫获取完所有信息后, 执行的内容, 比如我这里有将字典内的信息转换为数据框, 然后数据框内容写入文件, 另外就是把之前打开的文件句柄给关掉
4. 其他设置
如果有更改请求头, 挂代理, 设置访问间隔防止被封IP之类的需要, 那就回到demo/setting.py文件里去更改就好了.
5. 运行爬虫
这个最简单了, 项目目录里scrapy crawl demo, 然后就可以观察运行状况了, 工作日志会直接打印在屏幕上, 可以根据日志进行调试
小结
以上就是基本的使用了, 对Scrapy的工作方式进行小结的话, 就是我们需要自己定义爬虫要爬取什么网站, 然后在parse方法中写明如何解析请求返回的内容,
扩展
本次记录的爬虫案例有一个前提, 就是通过简单的get或post请求获得的响应就能包含我们想要获取的数据. 但是随着网页技术的发展, 月来越多网站不再是只有html的静态网站了… 大部分网站都多少有通过js加载的内容, 甚至整个网页都是js或其他框架渲染出来的, 这种时候简单的请求是无法取回想要的数据的, 也就要结合splash这样的渲染引擎一并使用了.
关于这个下次再记录.
以上~